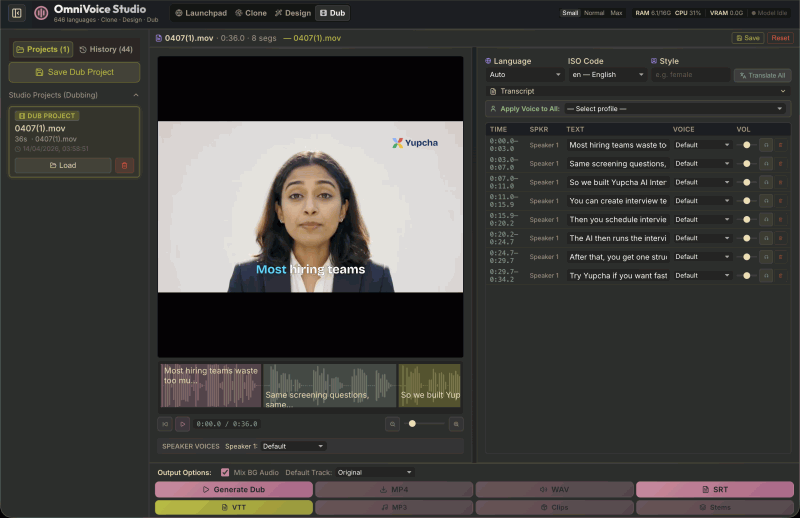
OmniVoice Studio:一个基于开源 OmniVoiceTTS 构建的本地化配音工作室,将视频转录、多语种翻译与高保真语音合成融为一体
在短视频和独立电影创作中,配音一直是最高昂的成本之一。你可能拥有完美的画面,却受困于生涩的 AI 机械音,或者在繁琐的“翻译-对轴-录音”流程中耗尽精力。
OmniVoice Studio 的出现,旨在将你的电脑变成一个全能的配音录音棚。它不仅是简单的文字转语音(TTS),而是一套完整的“视频再创作”流水线。从导入视频到最终合成带有完美对齐音轨的成片,一切都在本地私密运行。
一、 OmniVoice Studio是什么
OmniVoice Studio是一款基于开源OmniVoiceTTS引擎构建的深度配音协作平台。它专门面向“长内容”创作,如电影、纪录片和教学视频。其核心逻辑是通过 AI 自动处理音视频之间的对齐逻辑,让创作者能够在一个窗口内完成从原始视频转录到最终多语种配音输出的全部工作。
二、 核心特性
-
🎬 电影级全流程配音:支持“转录(ASR)→ 翻译(Translate)→ 合成(TTS)→ 复用(Multiplexing)”的完整工业链条。它能自动识别原片语速并动态调整生成语音的时长,确保音画同步。
-
📜 专业字幕联动输出:在生成配音的同时,系统会自动同步导出精准的 SRT 或 VTT 格式字幕文件。你可以选择输出纯配音音轨,或是直接封装好的配音版 .mp4 视频。
-
✨ 抛光玻璃美学设计:界面采用了极具未来感的“Glassmorphism(玻璃拟态)”设计系统。配备了灵动的微动画、沉浸式的对焦环交互以及深度定制的滚动条,让枯燥的后期工作变成一种视觉享受。
-
🧠 本地优先架构:核心引擎基于 OmniVoiceTTS,支持在本地高性能运行,无需担心素材上传导致的隐私泄露或昂贵的云端 API 账单。
-
🛠️ 灵活的扩展性:支持通过 API 接入不同的 LLM 进行翻译,或更换不同的 TTS 后端,满足从二次元配音到纪录片解说的多样化音色需求。
三、 安装与部署
-
Docker 一键安装:对于追求稳定的用户,推荐使用 Docker 部署。通过简单的 docker-compose up 指令,即可在镜像容器中完成所有复杂依赖环境的配置。
-
本地开发设置(Local Setup):开发者可以基于 Node.js 和 Python 环境进行手动配置。项目结构清晰,方便对 ASR 或 TTS 模块进行个性化调优。
-
环境兼容性:支持 CUDA 加速,在配备 NVIDIA 显卡的机器上,语音合成与视频渲染速度将获得数倍提升。
四、 开发计划(Roadmap)
-
原生桌面客户端:团队正致力于开发基于原生架构的 macOS、Windows 和 Linux 客户端,旨在脱离浏览器限制,提供更强悍的本地硬件调用能力和文件管理体验。
-
多角色声线克隆:未来计划引入更先进的零样本(Zero-shot)声线克隆技术,只需几秒样本即可复现特定人物的音色。
-
自动对口型(Lip-sync)增强:探索通过 AI 技术让画面中的人物口型与生成的配音自动匹配。
五、 产品定价
完全开源免费。
遵循开源社区精神,OmniVoice Studio 的所有核心代码均在 GitHub 公开。无论是个体创作者还是小型工作室,都可以自由地进行部署和二次开发,无需支付任何授权费用。
六、 使用场景
-
译制片与纪录片制作:快速将外语视频转化为母语配音版,同时保留原始背景音乐(BGM)和环境音。
-
教育培训课件:为教学演示视频一键添加多语种配音和字幕,助力课程出海。
-
自媒体矩阵运营:将一套视频素材快速低成本地转化成多个语言版本,分发至全球视频平台。
-
辅助功能开发:为无障碍内容提供高质量的音频解说自动生成。
七、 运作模式
OmniVoice Studio 采用了 “时间轴解构与重组” 的技术逻辑。
系统首先利用 Whisper 等模型将视频音轨转化为带有时间戳的文本(ASR)。随后,翻译模块将文本转化为目标语言,同时计算目标语言所需的正常语速时长。在 TTS 阶段,OmniVoice 引擎会根据时间轴余量进行动态伸缩(Time-stretching)合成,确保译文不会溢出或落后于画面。最后,通过 FFmpeg 自动分离原片人声并混入新音轨,实现高质量的成片交付。
结语
配音不应是创作的终点,而应是想象力的延伸。OmniVoice Studio 将复杂的声学算法隐藏在优雅的玻璃界面之下,让每一位创作者都能拥有属于自己的“数字配音组”。如果你想让你的视频更具国际范,或者渴望更高效的内容生产,这款开源力量驱动的 Studio 绝对值得你立刻部署体验。
项目网址: https://github.com/debpalash/OmniVoice-Studio